
SIDAP - Datenintegration und Datenanalyse
Big Data-Analysen scheitern meist an unstrukturierten Daten
-
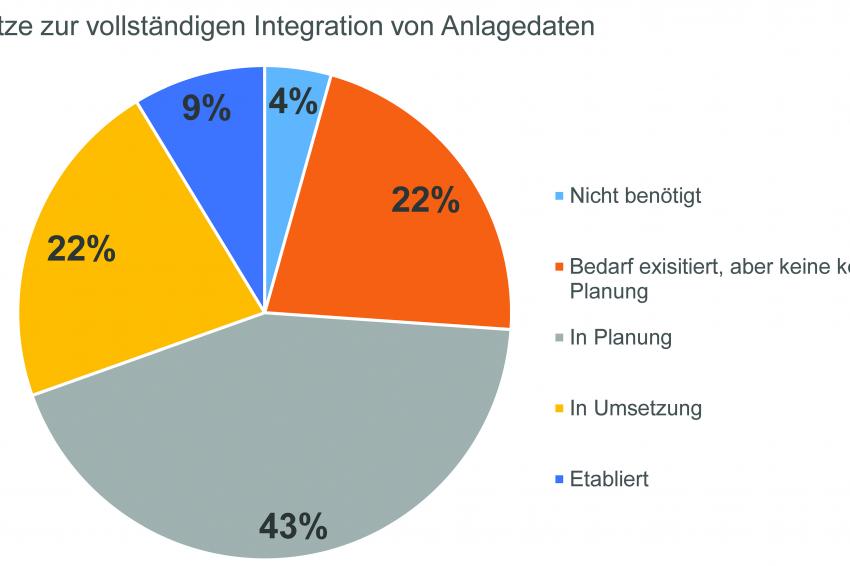 Vieles ist in Planung, aber wenig etabliert: Ergebnisse der Umfrage unter NAMUR-Mitgliedern zu Big Data-Analysen.
Vieles ist in Planung, aber wenig etabliert: Ergebnisse der Umfrage unter NAMUR-Mitgliedern zu Big Data-Analysen. -
 Unstrukturierte Daten werden als größte Herausforderung bei Big Data-Analysen angesehen.
Unstrukturierte Daten werden als größte Herausforderung bei Big Data-Analysen angesehen.
Big-Data-Analysen werden gerne als Schlüssel für zukünftige Industrie 4.0-Konzepte angesehen. In der Praxis stehen Anwender – besonders in der Prozessindustrie - bei der Umsetzung und Einführung solcher Methoden jedoch vor großen Herausforderungen. Ein Gemeinschaftsprojekt aus Industrie und Forschung zur skalierbaren Datenaggregation und –analyse und zur Aufbereitung von großen Datenmengen soll jetzt Hilfestellungen erarbeiten.
Um die Mechanismen, die einer Big-Data-Analyse im Weg stehen, genauer zu untersuchen, führte die Technische Universität München eine Umfrage unter NAMUR-Mitgliedern durch. In der NAMUR (Interessengemeinschaft Automatisierungstechnik der Prozessindustrie) sind derzeit 152 Unternehmen vertreten.
Big Data: Ja, aber …
Rund zwei Drittel der Befragten sind davon überzeugt, dass die Datenanalyse prinzipiell zur Optimierung von Anlagen geeignet ist. An erster Stelle wurde dabei die Unterstützung von Operatoren im laufenden Betrieb genannt, gefolgt von der Diagnose von Prozessen und Komponenten sowie einem verbesserten Verständnis für Zusammenhänge. Die Umsetzung verläuft jedoch in den Betrieben eher schleppend.
„Unstrukturierte Daten sind das größte Hindernis beim Einsatz von Big Data-Analysen in der Prozessindustrie“, erklärt Birgit Vogel-Heuser, Leiterin des Lehrstuhls Automatisierung und Informationssysteme an der Technischen Universität München. „Dies bestätigen auch die Ergebnisse unserer Umfrage.“ Messgeräte in chemischen Anlagen produzieren eine Vielzahl an Nutzungs-, Wartungs- und Qualitätsdaten. Diese werden aber meist in verschiedenen Datenbanken gesammelt und selten mit einer synchronen Zeitstempelung versehen. Zusammenhänge sind im Nachhinein schwer auszumachen, bzw. sie müssen für eine Analyse meist händisch zusammengefügt werden. Dies sind aber nicht die einzigen Herausforderungen. „Weiter wurden in der Umfrage die fehlende Definition eines allgemeinen Datenmodells, die Unterschiedlichkeit der Schnittstellen und der hohe Implementierungsaufwand bemängelt“, so Vogel-Heuser.
Skalierbares Integrationskonzept
Um die Herausforderung der unstrukturierten Daten besser zu meistern, entsteht derzeit mit SIDAP ein Skalierbares Integrationskonzept zur Datenaggregation, -analyse, -aufbereitung von großen Datenmengen in der Prozessindustrie. Daran arbeiten Betreiber (Bayer, Covestro, Evonik), Armaturenhersteller (Samson), Feldgerätehersteller (Krohne, Sick), IT-Unternehmen (Gefasoft, IBM) und die Technische Universität München zusammen. Hierbei sollen aus großen Datenmengen, die u.a. von vorhandenen Messgeräten stammen, neue Zusammenhänge ermittelt werden. Gleichzeitig wird eine datengetriebene sowie serviceorientierte Integrationsarchitektur entwickelt. Damit werden Messdaten, Informationen aus der Instandhaltung sowie Daten aus dem Engineering und den Prozessleitsystemen unter Berücksichtigung ihrer unterschiedlichen Semantik in abstrahierter, integrierter und zugriffsgeschützter Form für interaktive Analysen zugänglich. Erklärtes Ziel ist es, mit aufbereiteten Daten aus heterogenen Quellen die Anlagenverfügbarkeit zu erhöhen, indem Ausfälle vermieden und die Wartung angepasst wird.
Das Problem mit den Schnittstellen
Thomas Tauchnitz, Mitglied des Vorstands der NAMUR, weist aus Anwendersicht auf die Problematik fehlender durchgängiger Systeme hin: „Das Projekt SIDAP will die Daten prozesstechnischer Anlage nutzen, um daraus Wissen zu schöpfen, beispielsweise über Belastungen und Störungen von Ventilen. Dabei zeigt sich einerseits, dass – aufgrund der durchaus gewünschten hohen Zuverlässigkeit der Ventile – nur wenige Informationen über Schlechtzustände vorliegen. Und andererseits, wie aufwändig es ist, die Daten aus den verschiedenen Dateninseln zusammenzusammeln und in Beziehung zu setzen. Beispielsweise kennt ein Data Historian den Zeitverlauf von Stellsignal, Druck und Durchfluss, aber das Wissen um die zum jeweiligen Betriebszeitpunkt vorhandenen Stoffe ist im Rezeptsystem des PLS versteckt und die Stoffeigenschaften im Anlagen-Entwurfstool. Die Umfrage bestätigte, dass diese Probleme die Haupthindernisse für die Datenanalyse sind – man zahlt den Preis dafür, dass weder integrierte Engineering- und Automatisierungssysteme noch standardisierte Schnittstellen vorhanden sind.“
Innerhalb des Projekts SIDAP werden nur Prozessdaten im weiteren Sinne berücksichtigt – wie Sensorwerte, Auslegungsdaten, Wartungsberichte oder Stoffeigenschaften. Langfristig werden solche Analysen, dann jedoch mit einer anderen Zielsetzung, sicherlich auch weitere betriebliche Daten beinhalten.










