
Emerging Strategic Impact of Batch Analytics
The Value of Data Analytics on a Specialty Chemicals Company’s Market Position
-
 The Value of Data Analytics on a Specialty Chemicals Company’s Market Position (c) Rawpixel.com7Shutterstock
The Value of Data Analytics on a Specialty Chemicals Company’s Market Position (c) Rawpixel.com7Shutterstock -
 Artur Beyer, industry principal Chemicals, TrendMiner
Artur Beyer, industry principal Chemicals, TrendMiner -
 Fig. 1: Commoditization in chemicals
Fig. 1: Commoditization in chemicals -
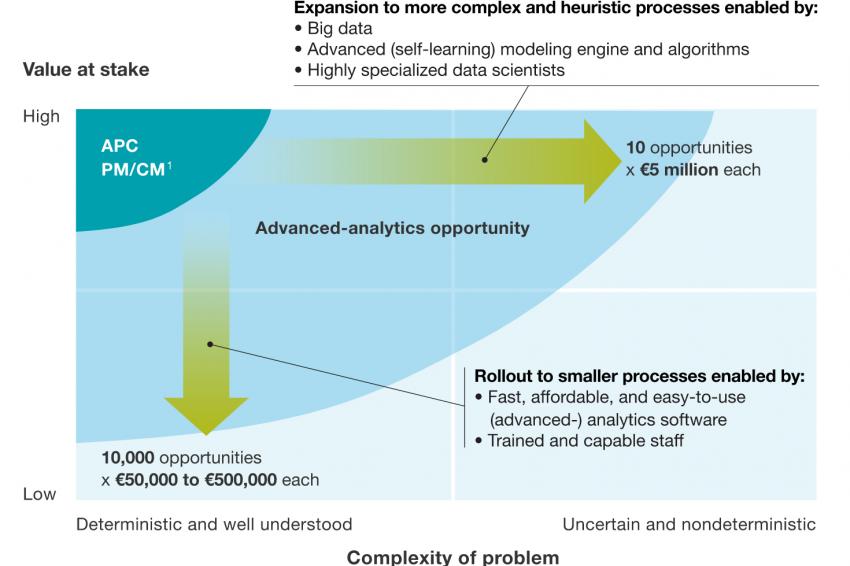 Fig. 2: Buried treasure – advanced analytics in process industries
Fig. 2: Buried treasure – advanced analytics in process industries
Recent significant investments by big chemical companies in a strong specialty chemicals portfolio indicate that the importance of these products and therefore of batch production is on the rise. Because of the value that data analytics could bring to their market position, forward-thinking companies have already moved ahead of the curve by digitalization of their production.
Pioneers in the chemical market have used trends like self-service analytics to create an analytics-enabled workforce in order to strengthen their market position and create the most profitable factories of tomorrow. The reasons for this change are firmly based in financials, such as the better performance with respect to return on invested capital (ROIC) which represents a company’s operating profitability.
Another important driver is to increase financial flexibility to safeguard the portfolio against commoditization, which can be done by getting as much out of the existing production capacity as possible. In a time where putting out new chemical compounds into the market is harder than ever before, sustainability is key. Next to an organizational strategy to build portfolios based on sustainable products based on known compounds, financial flexibility through operational excellence will be key for lasting success.
With plant-level process experts often tied up in a variety of tasks, ranging from maintenance planning over audits to frequent production meetings, the time to proactively investigate process performance issues is limited. Depending on the role in the organization, experience in the process industry has shown that the average time spent on data analytics is around 20%. In addition, data analysis as such is not a core competence taught during the standard education of a process expert. This leads to a skill gap that is hard to close in a short time, since rigorous data analysis and the needed algorithmic knowledge are not easy to learn.
Limitations in time available for data analysis and a likely data analysis skill gap often lead to priority-driven analysis in practice. The main focus is often on fire fighting and the more immediate history utilizing the tools that the historian systems and Microsoft Excel have to offer. Priority-driven analysis keeps the plant running but at the same time leads to missed opportunities in proactive process improvements. Those missed opportunities of improvement can be significant in value, ranging from $50.000 up to multi-million dollar savings per opportunity.
In general, batch production can be improved in the following areas:
- cycle time reduction
- identification of bottlenecks
- reduction of unplanned downtime
- root cause analysis of quality deviations
- golden batch monitoring
- prediction batch evolution
Contributions in those areas will significantly boost overall profitability of the plants through increases in throughput and quality. This typically can be achieved without structural investments in new equipment or even in completely new plants.
Batch Analytics in Practice
While batch analytics holds a lot of potential for recurring improvements of production costs, there are some practical challenges along the way that need to be tackled in the right way to ensure lasting success.
From experience, the main practical challenges to overcome, are:
- retrieval, analysis and monitoring of batch data with various expert systems across the value chain of analytics
- analyzing data across multiple assets
- leveraging (decentralized) knowledge about the process
Retrieval, Analysis and Monitoring of Batch Data
Analyzing process data starts with the availability of the relevant data. This is one of the biggest hurdles to overcome when attempting to start a data-driven analysis of a process issue. Data gathering usually takes a lot of time and effort and involves various historian systems and/or lab quality systems. Often data from both places needs to be combined. To solve this issue a live connection between the data analysis platform of choice and the various historian systems from different vendors across the organization is crucial. If the best practice of having the lab data available on the historian is not followed, the process expert also needs an easy way to connect to or at least upload data from the different lab systems that are out there. Now, the process engineer’s time is focused on applying his/her knowledge rather than taking care of getting the needed data into place.
Once the relevant data is connected to the analysis platform, the first step of the analytics value chain needs to happen: analyze the data for new insights and diagnose the root cause of the problem. The focus of the analysis should not just be on the recent but on the complete history of process data recorded to unlock the true value of the data and making it available to the process experts.
Analyzing the process involves many interactions within the operation. This, as well as outside factors such as production loads and varied human interactions, means that diverse situations may be rare and scattered throughout the data historian. To solve this problem, there needs to be a search engine for the process data that enables the process expert to quickly retrieve and assess the comparability of the situations of interest across the entire production history. Achieving a direct and efficient connection between the complete data history and the expert knowledge of the workforce unlocks the true value of the process data and is the foundation of any diagnostic exercise.
Diagnostic exercises ideally are based on advanced analytics with easy interpretable results and fast iterations with the process expert. A pattern recognition-based, responsive and easy way to analyze process data is the key to bringing recent advancements where they matter: to the process experts.
Once the process expert solves the issue at hand, ideally a monitor is set up that represents the next step in the analytics value chain. This can be partially done using the capabilities of the historian systems by utilizing value-based alerts and/or calculations. This is not always desired due to:
- overflooding of possibly irrelevant performance monitors
- lack of permission to configure a performance monitor on a central system
- ineffectiveness of value based monitors for batch production
- performance monitoring is implemented on a different system, which creates a dispersed environment
The process expert should have the opportunity to create performance monitors based on his analysis to keep up with the process performance metrics relevant for his role. In addition, the warnings must extend beyond value-based options and enable other dimensions such as dynamic multivariate patterns or fingerprints. If the configured performance monitor is crucial for the operators it can be pushed towards a central system.
The last step in the analytics value chain, which is currently rarely tackled, is prediction. As of today, the only way of predicting behavior of batches is the utilization of complex data models. Those models are hard to build, costly to maintain and the result is hard to interpret for the process experts. A solution is to enable predictive capabilities for the process experts. This leads to debottlenecking central data science departments and spreads the use of predictive analytics amongst process experts. For this to work, new ways of prediction beyond complex models, that are fast and iterative, easy to interpret, and robust need to be explored.
To achieve the above-mentioned prerequisites, new possibilities around pattern recognition emerge. Those techniques – which are fast, robust and visually accessible – enable predictions based on the current evolution of the relevant parameters and show the most probable evolution of the running batch based on how similar batches have evolved in the past.
Data Analysis across Multiple Assets
Production processes running multiple parallel lines are very common in batch production. Therefore, not just gathering data from all those production lines but also analyzing and monitoring across assets is a common challenge. Frequently data from identical plants around the world needs to be accessed, which increases the degree of difficulty even more. Gathering and analyzing data on such a scale is a huge time investment and is often neglected due to the restricted time of the process experts. Therefore, enabling all the capabilities mentioned in the previous section across various assets and plants on one platform is crucial to completely empower the organization’s workforce in batch analytics.
Decentralized Knowledge about the Process
In a technology driven market the company’s success in the segment of specialty chemicals is founded in technological advantages over the competitors. One of the biggest goals of every organization should be retaining knowledge and its availability for the relevant people in the organization. Usually, knowledge is not where it belongs; within a central knowledge base on top of the process data – providing the relevant context for the analysis to everyone who may need it. Hence, a process data analytics platform with an internal possibility of data contextualization or a connection to a central knowledge base is needed to overcome the challenge.
An Example across the Whole Value Chain of Analytics
There are many examples that both illustrate the challenges mentioned above as well as the validity of the proposed solutions. Here, a case of a global specialty chemical company is described, which ranges across the whole value chain of analyze, monitor and predict.
The reaction of a particular product had significant issues with cycle time and quality. Therefore, further investigation by the process experts was needed. Since the cooling behavior is known to be crucial for the outcome of the reaction, focus was first put here.
With immediate access to all the data stored in the historian there was no problem in getting the relevant process data ready for analysis. As the problem just occurred for one particular product, relevant production stretches have been isolated utilizing search queries. Further use of search capabilities resulted in a list of longer batches with quality problems. Statistical and visual comparison of those batches with previously isolated ideal runs clearly showed a signature cooling profile associated with a positive outcome of the batches. Based on those insights, a golden batch fingerprint has been created and used for monitoring and visual benchmarking. In addition, real-time predictions based on the dynamic patterns of the batch evolution have been used by the process experts to anticipate deviations from the ideal behavior.
The value gained from this analysis was a cycle-time reduction of three hours per batch and a significant reduction of quality deviations.
This case shows that empowering the process experts, to easily connect their expertise with the process data based on the solutions mentioned in the previous section (also known as self-service industrial analytics), is crucial to overcome the day-to-day challenges they face when analyzing process data of batch productions. Furthermore, it shows that the outcome is not only significant to reach production goals but also to strengthen the company’s market position by decreasing production costs.
Conclusion
In an ever more dynamic market, characterized by rapidly changing environments, immediate financial flexibility is key for a sustainable market position. Operational excellence is a big lever to achieve this flexibility. Data-driven process analysis and improvement is at the heart of operational excellence. Since this puts the process experts of the organization at center stage, it leads to the need of their analytics empowerment on a global scale. Only if the information hidden in the data is efficiently connected to the knowledge in the minds of the process experts, the organization can move towards a proactive data driven process improvement strategy.
On a practical level there are various challenges that need to be solved in the area of data availability, analytics and performance monitoring. Ideally a self-service industrial analytics solution is used, that helps the workforce to overcome those challenges and integrate all process experts rather than working with dispersed knowledge across various systems.



